Adobe Flash can make data difficult to extract. This tutorial will teach you how to find and examine raw data files that are sent to your web browser, without worrying how the data is visually displayed.
For example, the data displayed on this Recovery.gov Flash map is drawn from this text file, which is downloaded to your browser upon accessing the web page.
Inspecting your web browser traffic is a basic technique that you should do when first examining a database-backed website.
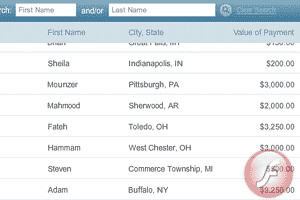
Flash applications often disallow the direct copying of data from them. But we can instead use the raw data files sent to the web browser.
Background
In September 2008, drug company Cephalon pleaded guilty to a misdemeanor charge and settled a civil lawsuit involving allegations of fraudulent marketing of its drugs. It is required to post its payments to doctors on its website.
Cephalon's report is not downloadable and the site disables the mouse’s right-click function, which typically brings up a pop-up menu with the option to save the webpage or inspect its source code. The report is inside a Flash application and disables copying text with Ctrl-C.
We asked the company why it chose this format. Company spokeswoman Sheryl Williams wrote in an e-mail: "We can appreciate the lack of ease in aggregating data or searching based on other parameters, but this posting was not required to do these things. We believe the [Office of the Inspector General]’s requirement was intended for the use of patients, who can easily look up their [health care provider] in our system."
Software to Get
- Firefox
- The Firebug plugin, to monitor your browser’s web traffic
- Ruby, the scripting language
- Nokogiri, an XML parsing library for Ruby
Instead of using Firebug, you can also use Safari's built-in Activity window, or Chrome's Developer Tools, for the inspection part. To parse the result, we use Ruby and Nokogiri, which is an essential library for any kind of web scraping with Ruby.
A Series of Tubes...and Files
While the site makes the data difficult to download, it’s not impossible. In fact, it’s fairly easy with some understanding of web browser interaction. The content of a web page doesn’t consist of a single file. For instance, images are downloaded separately from the webpage’s HTML.
Flash applications are also discrete files, and sometimes they act as shells for data that come in separate text files, all of which is downloaded by the browser when visiting Cephalon’s page. So, while Cephalon designed a Flash application to format and display its payments list, we can just view the list as raw text.
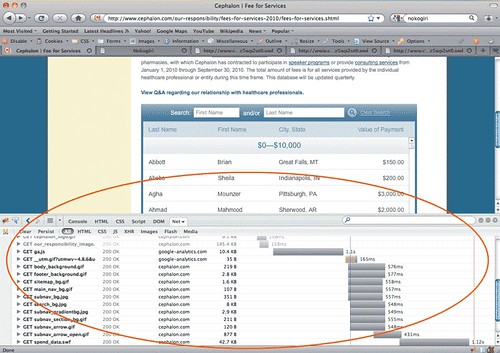
Viewing Cephalon's page. The Firebug panel is circled
Firebug can tell you what files your browser is receiving. In Firefox, open up Firebug by clicking on the bug icon on the status bar, then click on the Net panel. This panel shows every file that was received by your web browser when it accessed Cephalon's page.
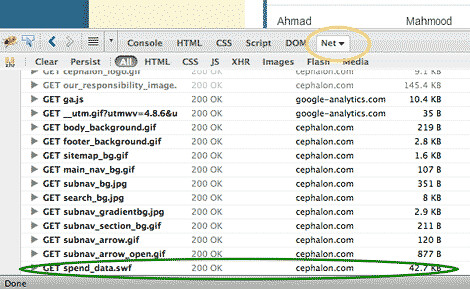
Close-up of the Firebug panel. The Net tab is circled in yellow, the relevant .swf file is circled in green.
We know we’re looking for the Flash file, so let's look for that first. Flash applets use the suffix swf. The only one listed is spend_data.swf. In Firebug, right-click on the listing, copy the url, and paste it into a new browser window:
http://www.cephalon.com/Media/flash/spend_data-2009.swf
You can see the Flash file in its context here: http://www.cephalon.com/our-responsibility/relationships-with-healthcare-professionals/archive/2009-fees-for-services.html.
You'll get a larger-screen view of the list, though that doesn’t really help our data analysis. As you may have noticed in the Firebug Net panel, spend_data.swf is less than 45 kilobytes, which doesn't seem large enough to contain the entire list of doctors and payments. So where is the actual data stored?
Sniffing Out the Data
Here’s how find it: First, clear your cache in Firefox by going to Tools->Clear Recent History and selecting Cache. With Firebug still open, refresh the browser window that has spend_data.swfopen.

Relevant XML file is circled here.
Firebug's window tells us that besides receiving spend_data.swf, our browser downloaded two xml files. One of these is more than 100 kilobytes, which is about what we would expect for an XML-formatted list of a few hundred doctors.
Now right-click on the file in Firebug and select Open in New Tab, and then View Page Sourceby right-clicking in the new tab. You should see a text file full of entries like the following:

That's what we were looking for: a well-structured list of the doctors and what they got paid. Now it's a simple matter of using an xml parser, like Ruby's Nokogiri, to iterate through each "row" node and pick up the essential values.
Parsing with Nokogiri
The following is a brief example of Nokogiri's most basic methods. It assumes you have Ruby andNokogiri installed, and a little familiarity of basic programming.
The two Nokogiri methods we're most interested in are:
- css – this lets us select tags inside XML and HTML documents. In this example, we want thevalue and row tags.
- text – with each element returned by css, text will give us the actual characters enclosed by the element's tags.
Each row represents a record, and each value represents a datafield, like name and location. So, we simply want to read each row and select the values we're interested in.

Here's a compact variation of the above code that writes the result into a file:

So, what first appeared to be the most difficult report to parse ends up being the easiest. Whether you’re dealing with a Flash application or a HTML database-backed website, your first step should be to see what text files your browser receives when accessing the page.
No comments:
Post a Comment